一、递归
1、# 递归 —— 在函数的内部调用自己 # 递归的最大深度 : 998,997,不到1000 递归函数记得加return,不然接收的是None # 小例子: # 猜年龄 # alex多大了 alex 比 wusir 大两岁 40+2+2 # wusir多大了 wusir 比 金老板大两岁 40+2 # 金老板多大了 40了 # age(1) # n = 1 age(2)+2 # n = 2 age(3)+2 # n = 3 age(3) = 40
def age(n): if n == 3: return 40 else: return age(n+1)+2 print(age(1)) 执行结果:44 执行记录分析:
# # n = 1 # def age(1): # if 1 == 3: # return 40 # else: # return age(2)+2 # # # n = 2 # def age(2): # if 2 == 3: # return 40 # else: # return age(3)+2 # # # n = 3 # def age(3): # if 3 == 3: # return 40
2、# 递归求解二分查找算法 # 算法 # 99*99 = 99*(100-1) = 9900-99 = 9801 # 人类的算法 # 99 * 99 # 算法 计算一些比较复杂的问题 # 所采用的 在空间上(内存里) 或者时间上(执行时间) 更有优势的方法。空间上(节省内存),时间上(执行时间)。 # 排序 500000万个数 快速排序 堆排序 冒泡排序 # 查找 # 递归求解二分查找算法 : 有序的数字集合的查找问题 举例1:二分查找加递归
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] # 列表不能变 例子1:
def cal(l,num,start,end): mid = (end - start)//2 + start if l[mid] > num : cal(l, num, start, mid-1) elif l[mid] < num: # 13 24 cal(l,num,mid+1,end) else: print('找到了',mid,l[mid]) cal(l,60,0,len(l)-1) 以上执行结果会报错:原因是60根本不在列表中,所以报错,最后start都比end大 
讲解:
# l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] # def cal(l,60,16,17): # mid =0 + 16 # if 56 > 60 : # cal(l, num, start, mid-1) # elif 56 < 60: # 13 24 # cal(l,60,17,17) #None # else: # print('找到了',mid,l[mid]) # # # # l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] # def cal(l,60,17,17): # mid = 0 + 17 # if 60 > 66 : # cal(l, num, start, mid-1) # elif 60 < 66: # 13 24 # return cal(l,60,18,17) # else: # print('找到了',17,66) # # def cal(l, 60, 18, 17): # if start 66: # cal(l, 60, 18,17) # elif 60 < 66: # 13 24 # cal(l, 60, 18, 17) # else: # print('找到了', 17, 66) # else: # print('没找到') 例子2:
找到列表中66的位置,l为列表,num是要查找的数,start是起始位置0,end是列表最长-1
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] # 列表不能变 def cal(l,num,start,end): mid = (end - start)//2 + start if l[mid] > num : cal(l, num, start, mid-1) elif l[mid] < num: # 13 24 cal(l,num,mid+1,end) else: print('找到了',mid,l[mid]) cal(l,66,0,len(l)-1) 执行结果: 找到了 17 66 执行顺序讲解: # l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] # def cal(l,66,0,24): # mid = 12 + 0 # if 41 > 66 : # cal(l, num, start, mid-1) # elif 41 < 66: # 13 24 # cal(l,66,13,24) # else: # print('找到了',mid,l[mid]) # # l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] # def cal(l,66,13,24): # mid = 5 + 13 # if 67 > 66 : # cal(l, 66, 13, 17) # elif l[mid] < num: # 13 24 # cal(l,num,mid+1,end) # else: # print('找到了',mid,l[mid]) # # l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] # def cal(l,66,13,17): # mid = 2 + 13 # if 55 > 66 : # cal(l, num, start, mid-1) # elif 55 < 66: # cal(l,66,16,17) # else: # print('找到了',mid,l[mid]) # 例子2改造: 在上述基础上,改造,解决传参太多的问题,但是改变了列表的长度
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] def cal(l,num=66): length = len(l) mid = length//2 if num > l[mid]: l = l[mid+1:] cal(l,num) elif num < l[mid]: l = l[:mid] cal(l, num) else: print('找到了',l[mid],mid) cal(l,66) 执行结果:找到了 66 0 列表变化过程: [42, 43, 55, 56, 66, 67, 69, 72, 76, 82, 83, 88]
[42, 43, 55, 56, 66, 67][66, 67][66]在例子2上再次改造:(这个是最标准的写法,既没有改变列表大小,又有return)
# 参数太多 -------- ??? # 找的数不存在 ———— 解决了 # print return ------- 解决
算法:找66的位置
def cal(l,num,start=0,end=None): # if end is None:end = len(l)-1 end = len(l)-1 if end is None else end if start <= end: mid = (end - start)//2 + start if l[mid] > num : return cal(l, num, start, mid-1) elif l[mid] < num: # 13 24 return cal(l,num,mid+1,end) else: return mid else: return None l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] print(cal(l,66)) 执行结果:17 找不存在的,60的位置
def cal(l,num,start=0,end=None): # if end is None:end = len(l)-1 end = len(l)-1 if end is None else end if start <= end: mid = (end - start)//2 + start if l[mid] > num : return cal(l, num, start, mid-1) elif l[mid] < num: # 13 24 return cal(l,num,mid+1,end) else: return mid else: return None l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] print(cal(l,60))
执行结果:None 二、模块 1、内置模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
举例1:
import collections d = collections.OrderedDict() print(d) # d['电脑'] = 10000 d['苹果'] = 10 print(d) for i in d: print(i,d[i]) print(d['电脑']) 执行结果:
OrderedDict()
OrderedDict([('电脑', 10000), ('苹果', 10)])电脑 10000苹果 1010000
举例2、time模块,底下的写法都可以
import time time.sleep() from time import sleep sleep()
举例3、
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in values: if value>66: my_dict['k1'].append(value) else: my_dict['k2'].append(value) # 默认这个字典的value是一个空列表 d = {} print(my_dict) my_dict['a'].append(1) my_dict['b'].append(2) my_dict['c'] = 10 print(my_dict) 执行结果: defaultdict(<class 'list'>, {'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]})
defaultdict(<class 'list'>, {'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90], 'a': [1], 'b': [2], 'c': 10})
举例4、
from collections import namedtuple Point = namedtuple('Point',['x','y']) p = Point(1,2) print(p.x) print(p.y) Card = namedtuple('card',['rank','suit']) c = Card('2','红心') print(c.rank,c.suit) 执行结果: 1
22 红心
举例5、
from collections import deque q = deque() q.append(1) q.append(2) q.append(3) q.append(3) print(q) print(q.pop())#打印出移除的对象 print(q) q.appendleft('a') #从左侧添加 q.appendleft('b') q.appendleft('c') print(q) print(q.popleft()) print(q.popleft()) 执行结果: deque([1, 2, 3, 3])
3deque([1, 2, 3])deque(['c', 'b', 'a', 1, 2, 3])cb
举例6、time模块
import time print(time.time()) # 时间戳时间 英国伦敦时间 1970 1 1 0 0 0 print(time.time()) # 时间戳时间 北京时间 1970 1 1 8 0 0 # 二进制 十进制 # 年月日时分秒 # 格式化时间 用字符串表示的时间 print(time.strftime('%H:%M:%S')) print(time.strftime('%Y-%m-%d %H:%M:%S')) print(time.strftime('%x')) print(time.strftime('%c')) print('{0},{1}'.format(1,2)) 执行结果: 1526104877.823745
1526104877.82374514:01:172018-05-12 14:01:1705/12/18Sat May 12 14:01:17 20181,2# 结构化时间 import time t = time.localtime() --可接收参数 print(t) 执行结果: time.struct_time(tm_year=2018, tm_mon=5, tm_mday=12, tm_hour=14, tm_min=2, tm_sec=30, tm_wday=5, tm_yday=132, tm_isdst=0)
# 时间戳 - 结构化时间 - 格式化时间
#time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致#time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间
import time print(time.time()) print(time.localtime()) 执行结果:
1526137587.3149958
time.struct_time(tm_year=2018, tm_mon=5, tm_mday=12, tm_hour=23, tm_min=6, tm_sec=27, tm_wday=5, tm_yday=132, tm_isdst=0)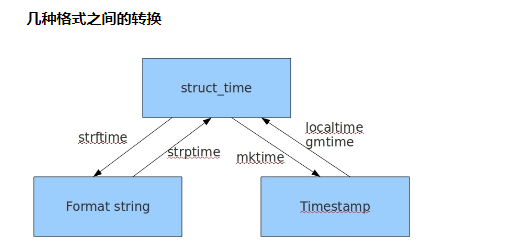
time.gmtime()#英国伦敦时间,比北京时间小8个小时(因为英国伦敦在子午线上)
import time print(time.time()) #单位是秒,时间戳时间 print(time.localtime(1500000000)) print(time.localtime(1600000000)) print(time.localtime(2000000000)) struct_time = time.gmtime(2000000000) print(time.strftime('%Y-%m-%d %H:%M:%S')) print(time.strftime('%Y-%m-%d %H:%M:%S',struct_time)) 执行结果: 1526104999.1826866
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)time.struct_time(tm_year=2020, tm_mon=9, tm_mday=13, tm_hour=20, tm_min=26, tm_sec=40, tm_wday=6, tm_yday=257, tm_isdst=0)time.struct_time(tm_year=2033, tm_mon=5, tm_mday=18, tm_hour=11, tm_min=33, tm_sec=20, tm_wday=2, tm_yday=138, tm_isdst=0)2018-05-12 14:03:192033-05-18 03:33:20
# # '2015-12-3 8:30:20' 时间戳时间 import time s = '2015-12-3 8:30:20' ret = time.strptime(s,'%Y-%m-%d %H:%M:%S') print(ret) print(time.mktime(ret)) 执行结果:
time.struct_time(tm_year=2015, tm_mon=12, tm_mday=3, tm_hour=8, tm_min=30, tm_sec=20, tm_wday=3, tm_yday=337, tm_isdst=-1)
1449102620.0
思考:
# 1.拿到当前时间的月初1号的0点的时间戳时间 # 2.计算任意 两个时间点之间经过了多少年月日时分秒 举例7、生成随机的四位数字
import random s = '' for i in range(4): s += str(random.randint(0,9)) print(s) 执行结果:6065
举例8、
# 数字 字母 print(chr(98)) # (65,90)A (97,122)a import random num = random.randint(65,90) print(chr(num)) num = random.randint(97,122) print(chr(num)) 执行结果:
b
Va


import datetimeimport timeapplyTime='2018-06-09 15:23:54'timeArray = time.strptime(applyTime, "%Y-%m-%d %H:%M:%S")timeStamp = int(time.mktime(timeArray))dateArray = datetime.datetime.fromtimestamp(timeStamp)#dateArray = datetime.datetime.utcfromtimestamp(timeStamp)#用这个utc的时间求出来会差8个小时 2017-12-11 07:23:54threeDayAgo = dateArray - datetime.timedelta(days = 180)print (threeDayAgo)执行结果:2017-12-11 07:23:54
可以参考:https://www.2cto.com/kf/201401/276088.html(Python时间,日期,时间戳之间转换)
举例9、生成任意四位字母数字组合--验证码
#某一位 到底是一个字母 还是一个数字的事儿也是随机的 import random id = '' for i in range(6): num = random.randint(65,90) alpha1 = chr(num) num = random.randint(97,122) alpha2 = chr(num) num3 = str(random.randint(0,9)) print(alpha1,alpha2,num3) s = random.choice([alpha1,alpha2,num3]) id+=s print(id) 执行结果:
C p 3
W q 1Y u 4H g 5D e 7K d 53quge5
举例10、sys模块
import sys # python解释器 sys.exit() # 解释器退出 程序结束 print('*'*10) print(sys.path) 执行结果: sys.exit()这个语句存在,print('*'*10)这个不再执行 # 一个模块是否能够被导入 全看在不在sys.path列表所包含的路径下 import sys print(sys.modules) # 放了所有在解释器运行的过程中导入的模块名 执行结果: {'builtins': , 'sys': , '_frozen_importlib': , '_imp': , '_warnings': , '_thread': , '_weakref': , '_frozen_importlib_external': , '_io': , 'marshal': , 'nt': , 'winreg': , 'zipimport': , 'encodings': , 'codecs': , '_codecs': , 'encodings.aliases': , 'encodings.utf_8': , '_signal': , '__main__': , 'encodings.latin_1': , 'io': , 'abc': , '_weakrefset': , 'site': , 'os': , 'errno': , 'stat': , '_stat': , 'ntpath': , 'genericpath': , 'os.path': , '_collections_abc': , '_sitebuiltins': , 'sysconfig': } import sys print(sys.argv) 执行结果: ['H:/MyProject/ke删除.py'](当前文件的路径)
import sys print(sys.argv) if sys.argv[1] == 'alex' and sys.argv[2] == 'alex3714': print('可以执行下面的n行代码') else: sys.exit() 执行会报错 # 在执行python脚本的时候,可以传递一些参数进来 # mysql username password 举例11、OS模块
# os模块 import os print(os.getcwd()) os.chdir(r'D:\EVA') print(os.getcwd()) open('aaaaaaa','w').close() # 文件创建到了当前工作目录下 # import os # 'path1%spath2'%os.pathsep 执行没结果
import os os.system("dir") # exec ret = os.popen('dir').read() print(ret) 执行结果: ������ H �еľ��� ������̬
������к��� A2E6-F99CH:\MyProject ��Ŀ¼
2018/05/12 14:23 <DIR> .
2018/05/12 14:23 <DIR> ..2018/04/22 19:30 <DIR> .idea2018/04/15 09:35 822 11111.py2018/05/02 19:32 7,349 5.2.py2018/04/13 23:39 220 99.py2018/04/04 22:50 2,596 day01.py2018/04/08 19:02 1,552 day01_zuoye.py2018/04/12 08:44 4,175 day02.py2018/04/10 22:32 4,458 day02.py2018/04/09 00:11 3,313 day02_01.py2018/04/18 07:06 2,273 day03kecheng.py2018/04/22 19:30 3,639 day04.py2018/05/03 08:26 2,291 day04.py2018/05/07 23:59 367 day05ketang.py2018/05/12 11:40 2,564 day05.py2018/05/02 21:02 109 employee2018/04/18 08:31 35 file_test2018/05/12 14:23 5,624 keɾ��.py2018/05/05 01:37 9,973 day04.py2018/04/18 08:03 38 log12018/04/18 08:13 3 log22018/04/22 13:42 27 test042018/04/06 23:33 752 testday01content.py2018/04/08 21:12 3,086 testday02.py2018/04/22 09:24 282 testday03.py2018/05/02 17:33 121 userinfo2018/04/15 10:31 <DIR> ����day01��ҵ2018/04/04 23:26 1,356 ����day01��ҵ.zip 25 ���ļ� 57,025 �ֽ� 4 ��Ŀ¼ 58,943,913,984 �����ֽ� 驱动器 H 中的卷是 工作固态 卷的序列号是 A2E6-F99CH:\MyProject 的目录
2018/05/12 14:23 <DIR> .
2018/05/12 14:23 <DIR> ..2018/04/22 19:30 <DIR> .idea2018/04/15 09:35 822 11111.py2018/05/02 19:32 7,349 5.2.py2018/04/13 23:39 220 99.py2018/04/04 22:50 2,596 day01.py2018/04/08 19:02 1,552 day01_zuoye.py2018/04/12 08:44 4,175 day02.py2018/04/10 22:32 4,458 day02.py2018/04/09 00:11 3,313 day02_01.py2018/04/18 07:06 2,273 day03kecheng.py2018/04/22 19:30 3,639 day04.py2018/05/03 08:26 2,291 day04.py2018/05/07 23:59 367 day05ketang.py2018/05/12 11:40 2,564 day05.py2018/05/02 21:02 109 employee2018/04/18 08:31 35 file_test2018/05/12 14:23 5,624 ke删除.py2018/05/05 01:37 9,973 day04.py2018/04/18 08:03 38 log12018/04/18 08:13 3 log22018/04/22 13:42 27 test042018/04/06 23:33 752 testday01content.py2018/04/08 21:12 3,086 testday02.py2018/04/22 09:24 282 testday03.py2018/05/02 17:33 121 userinfo2018/04/15 10:31 <DIR> day01作业2018/04/04 23:26 1,356 day01作业.zip 25 个文件 57,025 字节 4 个目录 58,943,913,984 可用字节举例12、
# win linux # 操作系统自己有的一种简单的语言 import os print(os.path.abspath('4.模块.py')) print(os.path.dirname(r'D:\EVA\周末班python21\day5\4.模块.py')) print(os.path.split(r'D:\EVA\周末班python21\day5\4.模块.py')) print(os.path.basename(r'D:\EVA\周末班python21\day5\4.模块.py')) print('\\n\\t\\t\\n') print(r'\n\t\t\n') # real print(os.path.dirname(r'D:\EVA\周末班python21\day5')) print(os.path.join('D:\\','EVA','PYTHON','AAA')) print(os.path.getsize(r'D:\EVA\周末班python21\day5\4.模块.py')) print(os.path.getsize(r'D:\EVA\周末班python21\day5')) ret = os.listdir(r'D:\EVA\周末班python21\day5') print(ret) sum = 0 for path in ret: if os.path.isfile(path) is True: sum+= os.path.getsize(path) print(sum) 计算文件大小 三、正则表达式 # 正则表达式 字符串匹配相关的操作的时候 用到的一种规则 # 正则表达式的规则 # 使用python中的re模块去操作正则表达式 # # 元字符 对一个字符的匹配创建的一些规则 # 这些规则是在正则表达式中有着特殊意义的符号 # 如果要匹配的字符刚好是和元字符一模一样 那么需要对这个元字符进行转义 # 量词 量词跟在一个元字符的后面 约束某个字符的规则能够重复多少次 # 正则表达式默认 贪婪匹配 会在当前量词约束的范围内匹配最多的次数
# findall找所有
import re ret = re.findall('\d+', 'eva1236 e12gon y1280uan') print(ret) 执行结果: ['1236', '12', '1280'] # search找第一个
# 返回的值不是一个直接的结果 而是一个内存地址 需要使用.group()取值 # 如果匹配不上 返回None 就不能group
ret = re.search('----', 'eva1236 e12gon y1280uan') if ret:print(ret.group()) 执行结果:空的什么都没有,因为没有匹配上
C:\Python365\python.exe H:/MyProject/ke删除.py
Process finished with exit code 0
import re ret = re.search('\d+', 'eva1236 e12gon y1280uan') if ret:print(ret.group()) 执行结果:1236 import re ret = re.search('\d*', 'eva1236 e12gon y1280uan') if ret:print(ret.group()) 执行结果:就是空的,什么都没有 #match
import re ret = re.match('^\d+', '1231eva1236 e12gon y1280uan') print(ret) if ret:print(ret.group()) # match在search的基础上 给每一条正则都加上了一个^ 执行结果: <_sre.SRE_Match object; span=(0, 4), match='1231'>
1231
作业:
ret = 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) ) print(ret) #2776672.6952380957 express = '1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )' # 2776672.6952380957 # eval # 先算小括号里的 # 再先乘除后加减的计算 # 'a*b' # 50行之内 # 三级菜单 递归 + 堆栈 # 时间模块 计算时间差 # random模块 发红包 验证码 # os 计算文件夹内所有文件的总大小
资料:
在线表达式工具:在线测试工具
正则表达式:http://www.cnblogs.com/Eva-J/articles/7228075.html